# 1 引言
# 1.1 课程内容简介
# 课程目标
- 理解操作系统的设计和实现。设计指具体结构,实现指具体代码。
- 通过现有的示例操作系统(XV6),对其进行扩展,并通过接口开发软件,以作为实践环节。
# 操作系统目标
- 硬件抽象。以便从高层次操作硬件,以获得更好的通用性和可移植性。
- 并发性。能够同时使用多个应用程序。
- 隔离性。能够隔离应用程序,防止 bug 的传播。
- 共享性。能够共享内存,从而进行数据交互。
- 安全性。拥有权限机制从而禁止或允许用户的操作。
- 高性能。操作系统应当能够发挥出硬件的全部性能。
- 生态。一个好的操作系统应当能够支持大量不同类型的应用程序。
# 1.2 操作系统结构
计算机的最底层是其所拥有的硬件资源,包括 CPU、内存、磁盘、网卡等。
最上层是用户空间,用户空间中运行着大量的应用程序。
Kernel(内核)运行在硬件资源和用户空间之间。它是一个特殊的应用程序,负责维护用户空间进程(支持上层)以及管理硬件资源(调用下层)。
内核提供多种服务,包括文件系统和进程管理系统、进程间通信服务、网络和硬件驱动等。
应用程序通过系统调用(System Call)访问内核,其形式类似函数调用,典型的系统调用有 open、write、fork 等。
# 1.3 挑战与乐趣并存
# 挑战
- 内核的编程环境恶劣,它并没有一个方便的软件基础,需要与底层的硬件资源交互。
- 操作系统的高效性和易用性之间的矛盾。高效性意味着操作层级应较低,而易用性则需要提供高层次的抽象接口。而对操作系统开发人员来说,我们又需要提供尽可能简单、却又功能性很强的接口。
- 应用程序的灵活性和安全性之间的矛盾。内核对应用程序的限制应尽可能小,从而保证其灵活性;但同时又要限制应用程序,以避免其对硬件的直接访问,从而破坏隔离性和安全性。
- 操作系统大量服务之间的交互是困难且复杂的。
- 操作系统需要紧跟硬件的发展。
# 乐趣
- 我们需要思考操作系统服务之间的交互方式,这应当是有趣的。
- 重新思考设计操作系统使其匹配最新硬件的过程是有趣的。
- 对计算机运行原理感兴趣,喜欢构建能够被其他应用程序使用的基础架构,或是为了定位操作系统级别的程序 BUG,都需要操作系统的知识。
# 1.4 read,write,exit 系统调用
//copy.c :copy input to output.
#include "kernel/types.h"
#include "user/user.h"
int main(){
char buf[64];
while(1){
int n=read(0,buf,sizeof(buf));
if(n<=0) break;
write(1,buf,n);
}
exit(0);
}
# read
int n=read(0,buf,sizeof(buf))
read 系统调用接受三个参数:
- 第一个参数是文件描述符,指向一个之前打开的文件。特别地,文件描述符 0 连接到 console 的输入,文件描述符 1 连接到 console 的输出。
- 第二个参数是指向某段内存的指针,程序可通过该指针读取相应地址内存中的数据。
- 第三个参数是代码读取的最大长度,在这里是 64 个字符。
一般情况下,read 的返回值是读取到的字节数。当遇到文件尾,read 返回 0;当发生错误,read 返回-1。
# write
write(1,buf,n);
write 系统调用同样接受三个参数,其与 read 相同。
# exit
exit 接受一个参数,当为 0 时代表正常退出,否则表示发生错误。
# 1.5 open 系统调用
int fd = open("output.txt", O_WRONLY | O_CREATE);
open 系统调用接受 2 个参数。第一个参数表示打开的文件名,第二个参数是标志位,表示在内核中的实现。
open 返回一个新分配的文件描述符,可被用来执行其他系统调用。
文件描述符对应内核维护的一个表单数据,包括该文件所包含的所有数据。每个进程都拥有独立的文件描述符空间。
# 1.6 fork 系统调用
int pid = fork();
if (pid == 0){
printf("child\n");
} else {
printf("parent\n");
}
fork 的作用是拷贝当前进程的内存,并创建一个新进程。两个进程独立运行。在新进程中,pid 返回 0;而在原始进程中,pid 返回新进程的 pid,它是一个大于 0 的整数。
# 1.7 exec,wait 系统调用
# exec
char *argv[] = {"echo", "this", "is", "echo", 0 };
exec("echo", argv);
exec 从文件中读取并加载指令,替代当前进程指令。第一个参数接受文件路径名,第二个参数接受传入的命令行参数。
Linux 中没有 exec,但有 exec 族函数。在此处比较接近的是 execv,位于
unistd.h中
exec 执行会替换当前进程,因此正常情况下无返回值,当前进程直接结束。因此我们通常将 exec 和 fork 组合使用。

# wait
wait(&status);
wait 接受一个 int 地址参数,内核会等待子进程完成,并将子进程的返回值写入。如果子进程成功,则 status 为 0,否则为 1。
exec-fork 风格系统调用代价是高昂的,它为了开启一个子进程往往需要复制整个内存。
# 1.8 I/O 重定向

I/O 重定向广泛用于 Unix 管道工具。它通过 >、< 等管道符改变默认的输出/输入文件符,从而实现 I/O 重定向。
# Lab1
- 获取源代码并切换到 util 分支
git clone git://g.csail.mit.edu/xv6-labs-2021
cd xv6-labs-2021
git checkout util
- 尝试编译运行 xv6
make qemu
遇到报错如下:
user/sh.c: In function 'runcmd':
user/sh.c:58:1: error: infinite recursion detected [-Werror=infinite-recursion]
58 | runcmd(struct cmd *cmd)
| ^~~~~~
user/sh.c:89:5: note: recursive call
89 | runcmd(rcmd->cmd);
| ^~~~~~~~~~~~~~~~~
修改 user/sh. c 文件,添加 noreturn 编译器属性以避免警告:
// Execute cmd. Never returns.
__attribute__((noreturn))
void
runcmd(struct cmd *cmd)
编译成功
xv6 kernel is booting
hart 1 starting
hart 2 starting
init: starting sh
$
- sleep 程序
在 user/user. h 中创建如下别名以解决报错,或选择在 user/sleep.c 中引入 ../kernel/types.h 头文件:
#define uint unsigned int
//or
#include "../kernel/types.h"
编写 user/sleep. c:
#include "user.h"
int main(int argc, char **argv) {
if (argc <= 1) {
printf("lack args\n");
exit(1);
}
sleep(atoi(argv[1]));
exit(0);
}
修改 makefile:
UPROGS=\
...
$U/_sleep\
重新编译并运行:
$ sleep
lack args
$ sleep 10
$
- ping-pong 程序
c 语言中管道图示如下:
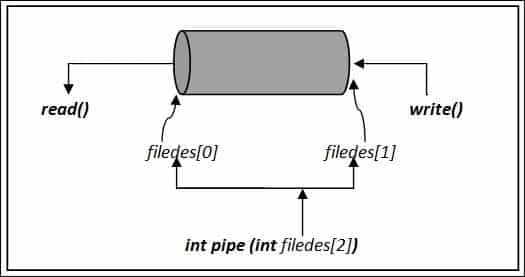
#include "user.h"
int main() {
int p1[2],p2[2];
pipe(p1);
pipe(p2);
if (fork() == 0) {
char buf[32];
close(p2[0]);
close(p1[1]);
//read ping
read(p1[0], buf, 4);
printf("%d: received %s\n", getpid(), buf);
close(p1[0]);
//write pong
write(p2[1], "pong", 4);
close(p2[1]);
exit(0);
} else {
char buf[32];
close(p1[0]);
close(p2[1]);
//write ping
write(p1[1], "ping", 4);
close(p1[1]);
//read pong
read(p2[0], buf, 4);
printf("%d: received %s\n", getpid(), buf);
close(p2[0]);
exit(0);
}
}
注意修改 makefile(下同)。结果如下:
$ pingpong
4: received ping
3: received pong
$
- 素数虽然难度标的是 hard,但其实并不太难,只是需要灵活应用 pipe:
#include "user.h"
int work(int *p, int n) {
// 读取上一个管道传入的数据
int num;
read(p[0], &num, 4);
close(p[0]);
// 递归退出条件:无法被整除,表明是素数,打印
if (n == 1) {
printf("prime %d\n", num);
return 0;
}
// 若不能被整除,则新建一个管道并递归,否则返回
if (num % n != 0) {
int p1[2];
pipe(p1);
write(p1[1], &num, 4);
close(p1[1]);
work(p1, n - 1);
}
return 0;
}
int main() {
// 倒序判断是否是素数
for (int i = 1; i < 36; i++) {
int p[2];
pipe(p);
write(p[1], &i, 4);
work(p, i-1);
close(p[1]);
}
exit(0);
}
结果如下:
$ primes
prime 2
prime 3
prime 5
prime 7
prime 11
prime 13
prime 17
prime 19
prime 23
prime 29
prime 31
$
- find 程序
#include "../kernel/types.h"
#include "../kernel/fs.h"
#include "../kernel/stat.h"
#include "../user/user.h"
// 获取文件的base name
char *getname(char *path) {
char *p;
// Find first character after last slash.
for (p = path + strlen(path); p >= path && *p != '/'; p--)
;
p++;
return p;
}
void find(char *path, char *filename) {
char buf[512];
int fd = open(path, 0);
struct stat st;
struct dirent de;
fstat(fd, &st);
switch (st.type) {
// 如果path指示一个文件,则比较base name
case T_FILE:
if (strcmp(filename, getname(path)) == 0)
printf("%s\n", path);
break;
// 若path指示一个目录,则递归搜索目录下的所有路径
case T_DIR:
// 处理路径,添加分隔符
strcpy(buf, path);
char *p = buf + strlen(buf);
*p++ = '/';
while (read(fd, &de, sizeof(de)) == sizeof(de)) {
if (de.inum == 0 || strcmp(de.name, ".") == 0 ||
strcmp(de.name, "..") == 0)
continue;
// 处理路径,将读取到的文件/目录名追加到buf作为查找路径
memmove(p, de.name, DIRSIZ);
p[DIRSIZ] = 0;
find(buf, filename);
}
break;
}
close(fd);
}
int main(int argc, char *argv[]) {
if (argc < 3) {
printf("args is too short\n");
exit(1);
}
find(argv[1], argv[2]);
exit(0);
}
结果如下:
$ echo > a
$ mkdir b
$ echo > b/a
$ find . a
./a
./b/a
$
- xargs 程序
#include "../kernel/param.h"
#include "user.h"
int main(int argc, char *argv[]) {
// 初始化参数列表
char *params[MAXARG];
// 判断xargs后的参数
if (argc > 1) {
for (int i = 1; i < argc; i++) {
params[i - 1] = argv[i];
}
} else {
printf("error\n");
exit(1);
}
params[argc] = 0;
// 从stdin读取参数,追加到参数列表最后
// 注意这里的数组大小,若太大则可能溢出;
char *buf[64];
int i = 0;
while (1) {
int len = read(0, &buf[i], 16);
if (len == 0 || buf[i] == (char *)'\n') {
break;
}
i++;
}
buf[i] = 0;
params[argc - 1] = (char *)buf;
// 建立子进程,主进程等待
if (fork() == 0) {
exec(params[0], params);
} else {
wait(0);
}
exit(0);
}
结果如下:
$ echo hello too | xargs echo bye
bye hello to
# 2 系统结构与系统调用
# 2.1 操作系统隔离性
# 为何需要隔离性
- 应用程序之间需要隔离性:在操作系统上运行的应用不应该不必要地影响其他正在运行的应用程序。
- 应用程序和操作系统之间需要隔离性:应用程序的崩溃不应该导致整个操作系统崩溃,要求操作系统有处理异常的能力。
# 操作系统隔离性的实现
操作系统通过抽象阻止应用程序直接访问硬件资源,如进程是 CPU 的抽象、文件是磁盘的抽象。借助操作系统的抽象接口,能够实现多个应用程序复用计算机硬件资源,同时满足强隔离性的目的。
# 2.2 操作系统防御性
# 为何需要防御性
- 操作系统需要应对恶意应用程序,防止恶意应用程序使操作系统崩溃。
- 操作系统应当保持对应用程序隔离,防止应用程序获取内核权限从而控制硬件资源。
操作系统防御性是隔离性的表现之一。操作系统借助硬件支持,包括用户/内核态(user/kernel mode)和 page table(页表,或虚拟内存)实现强隔离。
# 2.3 硬件对于强隔离的支持
硬件对于强隔离的支持包括:user/kernel mode 和 page table。
# user/kernel mode
处理器具有两种操作状态:当运行在用户态时,只能够执行普通权限指令;当运行在内核态时,能够执行特殊权限指令。
普通权限指令包括寄存器的加减、跳转操作;特殊权限指令与硬件状态相关,如设置 page table 寄存器和控制时钟中断。
假如应用程序打算执行一条特殊权限指令,会由于用户态而拒绝执行。这时 CPU 会跳转到内核态,并且杀掉进程。
对于 RISC-V,处理器还具有第三种状态:机器态(machine mode)。机器态拥有最高的特权级别,能够执行任何指令,主要用于处理器初始化和异常/中断处理。
# 虚拟内存
page table 提供了虚拟内存地址和物理内存地址的对应关系。每一个独立进程都维护着一个独立的 page table,保证其物理内存地址不重叠,使其无法访问到其他应用程序的内存,从而保证了内存的隔离性。
# 用户态/内核态切换
用户态和内核态划定了用户空间和内核空间的界线:应用程序运行在用户空间,而内核程序运行在内核空间。
应用程序通过系统调用转移控制权给内核。在 RISC-V 中,通过 ECALL 指令转移控制权。
ecall <uint>
ECALL 接受一个数字,可跳转到内核中特定的系统调用接入点。应用程序通过 syscall 函数发起系统调用,syscall 调用 ECALL,从而完成用户态/内核态切换。
# 2.4 宏内核与微内核
# TCB
TCB 即被信任的计算空间(Trusted Computing Base),代指安全的内核。一个安全的内核应当具有以下特征:
- 内核应当具有尽可能少的漏洞。
- 内核应当认为所有应用程序都是恶意的。
所有敏感的操作都应当运行在内核态,也就是 TCB 当中。
# 宏内核
所有操作系统服务均运行在内核态,这样的操作系统内核称为宏内核。绝大多数的 Unix 操作系统均是宏内核。
- Pro:宏内核组件具有良好的集成性,因此具有不错的性能
- Cron:由于服务都运行在内核中,宏内核发生故障的可能性更大。
# 微内核
微内核只在内核中提供了最基本的服务,以减少内核中的代码量。在微内核中,原本由内核提供的服务现在以一个用户程序的形式运行。
- Pro:微内核代码量少,发生 Bug 的可能性更低,因此更加安全。
- Cron:需要在用户态和内核态之间反复跳转,也同时更难共享内存,从而带来性能损耗。
# 2.5 编译运行内核
# xv6 的代码结构
- kernel:kernel 中包含了所有内核代码,这些代码编译成一个名叫 kernel 的二进制文件,该二进制文件运行在内核态中。
- user:user 中包含了所有的用户程序。
- mkfs:mkfs 创建一个空的文件镜像,通过挂载到磁盘上得到一个空的文件系统。
# 内核编译过程
- 编译:对每个. c 文件经编译器得到. s,这是 RISC-V 汇编代码文件
- 汇编:对. s 文件调用汇编器,形成. o,这是汇编代码的二进制形式
- 链接:使用系统加载器(Loader)链接成内核文件 kernel
这里所说的系统加载器也就是链接器(Linker)
# 2.6 xv6 启动过程
这部分内容比较零碎,由 claude 进行总结,我只是进行了一些整理和调整
- XV6 的入口地址是
0x80000000, 这个地址是 QEMU 要求的硬性条件, XV6 的载入器kernel.ld会将内核加载到这个地址开始。 - XV6 首先在
entry.s中启动,此时还没有内存分页和进程隔离,处于 machine mode。XV6 会尽快切换到 supervisor mode。 - 其他初始化工作:
- consoleinit: 初始化控制台,用于后续打印输出;
- kinit: 初始化页表分配器;
- kvminit: 初始化虚拟内存管理
- kvminithart: 打开页表
- processinit: 初始化进程表
- trapinit/trapinithart: 初始化用户/内核模式切换
- plicinit/plicinithart: 初始化中断控制器 PLIC
- binit: 初始化缓冲区缓存
- iinit: 初始化 inode 缓存
- fileinit: 初始化文件系统
- virtio_disk_init: 初始化磁盘
- userinit: 创建初始进程,并返回用户空间。这个初始进程定义在 initcode 中,它发起第一个系统调用,通过 exec 调用 init 程序。exec 系统调用由 sys_exec 函数处理,它将从用户空间读取参数并启动 init 进程。
- init 进程配置控制台,调用 fork 启动 shell。
- 最后 shell 被执行,XV6 启动完成。
所以,XV6 的启动过程可以概括为: 执行一系列初始化函数配置系统环境 -> userinit 启动第一个用户进程 -> 该进程执行 exec 系统调用启动 init 进程 -> init 进程 fork 出 shell 进程 -> shell 被执行,系统启动完成。
# Lab2
# System call tracing
- 添加文件到 makefile
$U/_trace\
- 在
user/user.h声明函数头文件;在user/usys.pl中添加存根;在kernel/syscall.h中添加系统调用的数值代号
// user/user.h
int trace(int);
// user/usys.pl
entry("trace");
// kernel/syscall.h
#define SYS_trace 22
- 在
kernel/syscall.c中添加声明;修改kernel/proc.c中的 proc 结构体,增加一个 mask 字段;在kernel/sysproc.c中实现sys_trace()函数。
// syscall.c
extern uint64 sys_trace(void);
static uint64 (*syscalls[])(void) = {
...
[SYS_trace] sys_trace,
};
// proc.c
struct proc {
...
int mask;
};
// sysproc.c
uint64 sys_trace(void) {
int mask;
//从寄存器中取值
if (argint(0, &mask) < 0) {
return -1;
}
myproc()->mask = mask;
return 0;
}
- 修改
kernel/proc.c中的fork函数,以从父进程复制到子进程的跟踪掩码
//proc.c
int fork(void){
...
np->mask = p->mask;
...
}
- 修改
kernel/syscall.c中的syscall函数,打印输出
void
syscall(void)
{
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
p->trapframe->a0 = syscalls[num]();
if ((1 << num) & p->mask) {
printf("%d: syscall %s -> %d\n", p->pid, syscalls[num], p->trapframe->a0);
}
} else {
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
# Sysinfo
# 3 虚拟内存
虚拟内存是对物理内存的抽象,它提供虚拟地址空间到物理地址的映射,是计算机隔离性的重要环节之一。
现代计算机均通过某种方式对虚拟内存提供了硬件支持。
# 3.1 地址空间
# 地址空间的必要性
程序必须存在于物理内存当中,假若不具有隔离性,很可能会破坏其他应用程序甚至操作系统的正常运作。我们通过向每个程序提供独立的地址空间来实现必要的隔离性。
# 3.2 页表
# 如何创建地址空间
我们通过页表创建独立的地址空间。页表在硬件中通过处理器和内存管理单元实现。
对任何涉及地址的指令,其使用的均是虚拟地址。虚拟地址会被转到内存管理单元(MMU,Memory Management Unit)并翻译成物理地址,由得到的物理地址去索引物理内存。
# MMU 如何翻译虚拟地址
为了完成虚拟地址到物理地址的映射,MMU 需要在内存中保存一份表单,表单地址保存在 CPU 的寄存器中(在 RISC-V 中是 SATP 寄存器)。
每一个应用程序应当保存了一份自己的表单,在切换应用程序中,SATP 中的内容也必须做相应的切换。
# RISC-V 中虚拟内存的实现
虚拟地址和表单不是一对一的关系。在 RISC-V 中,一个 page 的大小是 4KB。
对于一个虚拟地址,它的内容分为 index 和 offset 两部分。MMU 通过 index 找到物理内存 page 号,通过 page 起始地址加上偏移量从而找到物理地址。
RISC-V 寄存器是 64 位,最大支持 64 位虚拟地址;但高 25 位并未使用,因此最大支持 2^39,即 512G 内存。其中 27 位作为 index,12 位作为 offset,对应 page 的 4096 字节。
RISC-V 最大支持 56 位物理地址,因此最大内存理论上最多能够到达 2^56 字节。其中 44 位物理 page 号,12 位 offset(直接从虚拟地址中拷贝)。
在 RISC-V 中,page-table 是一个多级结构。

虚拟地址的 27 位 index 又细分为 L2、L1、L0,依次对应高、中、低级 page directory。每级 page directory 索引 512 个条目,每个条目(PTE)占 8 字节。在索引时,从高到低依次索引,然后在最低级的 page directory 中可得到实际物理地址。
分级结构很容易理解:通过将一个大的表单拆分多个小的表单,我们可以不索引许多没有用到的 PTE,从而大大减少了内存开销。
一个 page directory 分为 44 位 PPN(page 起始地址)和 10 位标志位,其他 10 位作为拓展位留空。标志位包括:
- Valid:表明 PTE 是否合法,合法(被使用)的 Valid 置一,否则置零。
- Readable 和 Writable,表明是否可读写 page
- Executable:是否可从该 page 执行指令
- User:是否可被用户空间进程访问
- 其他:不重要
# 3.3 页表缓存
三级寻址需要三次内存读取,因此代价较高,所以需要缓存最近读取过的内存地址,该技术称为页表缓存(TLB,Translation Lookside Buffer)。
TLB 会保存查询到的虚拟地址到物理地址的映射关系,在下一次访问同一虚拟地址时可直接从 TLB 中查取,从而避免查询 page table。在 table page 切换后 TLB 也会清空(RISC-V 中通过 sfence_vma 指令)。
# 3.4 xv6 页表实现
# 物理内存分布
物理地址寻址由具体主板决定,一般来说,从某个物理地址分隔(教程中是 0x80000000),以上是从 DRAM 寻址,以下是 I/O 设备。

上电后,主板运行 boot ROM 中的代码,然后跳转到 0x80000000,从而启动操作系统。
# xv6 虚拟地址空间
处于简单考虑,在 xv6 中,虚拟地址和物理地址的映射是相等映射。但是,虚拟地址和物理地址之间的映射关系可能是一对一、一对多、多对一。
我们还可以为 page table 设置权限,从而提早发现和处理 bug。
# 3.5 kvminit 函数
kvminit 函数设置地址空间。其结构如下:

- 代码的最上方为最高级 page 分配内存,并将内存置零
kvmmap函数将 I/O 设备映射到内核- vmprint 打印当前的 kernel page table
# 3.6 kvminithart 函数
kvminithart 函数运行在 kvminit 函数之后。

kvminithart 的作用是告知内核使用已经设置好的 page table,在此之后虚拟内存开始工作。
# 4 RISC-V 调用约定和栈结构
# 4.1 C 程序到汇编的转换
C 程序无法直接被计算机理解。计算机能够理解的是二进制代码,或者说 ISA(指令集)所对应的汇编语言。因此,需要将 C 程序经过编译(包括编译、汇编、链接等)变成汇编语言。
# 4.2 RISC-V 和 x86
RISC-V 是一种精简指令集(RISC,Reduced Instruction Set Computer),而 x86 是复杂指令集(CISC,Complex Instruction Set Computer)。两者主要区别如下:
- RISC-V 指令数量远小于 x86,x86 存在历史包袱;
- RISC-V 指令更加简单(封装程度低);
- RISC-V 是唯一的开源指令集;
# 4.3 RISC-V 寄存器
RISC-V 寄存器结构如下:

汇编代码运行在寄存器上,寄存器是运算和数据读取的最快方式。
第一列寄存器名称只在 Compressed Instruction(16bit)中有用,在其他地方使用 ABI 名称进行调用。
a0-7 寄存器保存函数参数,当参数数量大于寄存器数量时需要使用内存,因此会降低效率。
我们可以从 Saver 列查看寄存器的 Saver 类型,它有两个可能的值:Caller 和 Callee。其中 Caller 寄存器在函数调用时不会保存,也就是说它可以被调用函数重写。
# 4.4 栈
每次调用函数都会产生一个栈帧。它通过栈指针分配内存。由于栈帧是从高地址到低地址,因此当创建一个栈帧时对地址做减法。

栈帧中有两个重要的寄存器:fp 指向栈帧顶部,sp 指向栈帧底部。
一个栈帧中的第一位保存着自己的返回地址,然后是指向前一个栈帧的指针,以便函数返回。返回地址保存在 sp 寄存器中,指向前一个栈帧的指针保存在 fp 寄存器中。

上面的函数调用了一个名为 sum_to 的函数,因此必须包含 prologue:首先将 sp 寄存器减 16 以创建一个新的栈帧,然后将返回地址保存在 sp。

在函数调用的最后加载返回地址到 ra 寄存器,然后对栈指针加 16 以删除创建的栈帧。
# 4.5 结构体的结构
结构体在内存中是一段连续的地址,类似于一个数组,但每个字段的类型不需要相同。
# 5 隔离与系统调用的进入和退出
# 5.1 Trap
用户空间和内核空间的切换成为 trap,它发生在:
- 系统调用
- 发生 page fault 或除零错误
- 中断
# trap 流程
- 保存 32 个用户寄存器,以便在调用完成后恢复原来状态
- 保存 pc (程序寄存器)
- 更改 mode 标志位为 supervisor mode,以读写控制寄存器
- SATP 寄存器保存 page table 的物理地址,需要将其从 user page table 切换到 kernel page table
- 将堆栈寄存器(fp、sp)指向内核中的地址以调用内核代码
- 跳转到内核空间
# 5.2 Trap 代码执行流程
以 write 函数为例,它调用 ecall 切换到内核空间:
- 调用 uservec 函数
- 调用 usertrap 函数
- 执行 syscall,找到并调用 sys_write,打印到控制台并返回到 usertrap 函数
- usertrap 在最后执行 usertrapret,完成返回用户空间的部分准备工作
- 执行 userret 函数
# 6 Page faults
# 6.1 page fault 基础
虚拟内存的主要优点是:虚拟内存提供了应用之间以及用户空间与内核空间之间的隔离性;另外,虚拟内存提供了一层抽象,实现了虚拟地址和物理地址之间的动态映射。
page fault 能够动态更新 page table,我们能够利用 page fault 进行一些操作系统的优化行为。响应 page fault 需要记录以下几个信息:
- 触发 page fault 的源,也就是引起错误的虚拟内存地址。当 page fault 被触发,会进入 trap,并将错误地址保存在 STVAL 寄存器中。
- 出错的原因。即 trap 中状态切换的原因,用数字代号表示,保存在 SCAUSE 寄存器中。
- 触发 page fault 的指令地址,即发生错误的程序计数器的值,标志 page fault 在用户空间发生的位置,以便修复 page table 后可以恢复中断的指令。存储在 SEPC 寄存器以及
trapframe->epc中。
# 6.2 懒内存分配

在 RISC-V 中使用 sbrk 系统调用进行应用程序的内存分配。在应用程序启动时,sbrk 指向 heap 的底部,也就是 stack 的顶部,由 p->sz 标志。sbrk 接受一个整数参数,指示分配的字节数(页数?),以扩大 heap。
sbrk 默认的机制是 eager allocation,即积极的分配策略,在调用时立刻分配内存。但这非常容易造成内存浪费的问题。因此我们可以利用 page fault 实现 lazy allocation。
懒分配是指不立即分配内存,而是在发生由于内存未分配造成的 page fault 时执行 handler:使用 kalloc 分配一个内存 page,使用 0 填充内容以初始化并映射到 user page table,然后重新执行指令。
原始的 sbrk 函数如下,它将 p->sz 加 n 并分配内存:

而我们只想让其加 n,但不分配内存:

这样就会如期发生 page fault,我们在 usertrap 函数中对其 (SCAUSE=15) 进行处理,为其分配内存,若无物理内存则 kill 进程:

# 6.3 Zero-Fill-On-Demand
用户程序的地址空间中存在 data、text、bss 三个区块,其中,text 存放程序指令,data 区域存放已初始化的全局变量,bss 包含未初始化或初始化为 0 的全局变量。
在程序初始化时,我们需要分配许多内容为 0 的 page。通过使用按需分配策略,可以只初始化一个全零的物理 page,同时将虚拟地址空间挂载到这个物理 page 之上。这个 page 应当是只读的。在尝试读写这个 page 时,会发生 page fault,我们在 handler 中新分配一个全零的 page,并重新进行操作。
它带来的好处是我们不需要在一开始就为应用程序分配大量内存,它能够减少内存的用量,同时加快应用程序的启动速度。但是 page fault 处理会增加一定成本。
# 6.4 COW Fork
COW Fork 即 Copy-On-Write Fork,它使用写时复制策略。它尝试解决的问题是:当我们同时调用 fork 和 exec 时,fork 会创建新的 page,并将父进程的 page 拷贝到子进程 page 当中;但执行 exec 后,它又会抛弃这些 page(也就是说这部分内存不会被修改),并分配新的 page 来执行新的指令内容。
COW Fork 所做的就是让子进程共享父进程物理内存 page,也就是设置子进程的 PTE 指向父进程的物理内存 page。出于隔离性考虑,我们将子进程和父进程的 PTE 均设置为只读。因此,当尝试更改内存内容时会发生 page fault。这时可以为子进程创建新的 page,该 page 只对子进程可见,而原 page 对父进程可读写。
# 6.5 Demanding Paging
在 exec 执行后,需要加载内存的 data 和 text 到 page 中。操作系统默认使用 eager 的方式进行加载。demanding paging 也就是事先在虚拟空间中分配好 data 和 text 的地址段,但不对应任何实际的物理地址,即将 PTE 的 valid bit 设为 0。
当应用程序从地址 0 开始执行,当遇到 on-demand page 时会触发 page fault,这时我们从内存中读取程序 page 数据,然后将其映射到 page table 再重新执行。
当不是全部的 data 和 text 被用到时,通过这种方式我们可以节省内存的使用,同时加快程序的运行速度。
当物理内存耗尽时,一种方法是撤回 page,也就是将其写回文件系统,并释放该 page。
我们通常使用 LRU(Least Recently Used)策略决定将要撤回的 page。page 分为 dirty 和 non-dirty page:dirty page 曾经被写,而 non-dirty page 只被读过。我们比较倾向选择 non-dirty page,因为 dirty page 需要再次被写回到内存中,因而对其写的成本更高。
在 PTE 中的 RSW 寄存器中存有 Dirty 和 Access bit,这两个 bit 标志该 PTE 是否是 dirty 以及在何时被访问过,因此可以用 Access bit 来决定 LRU 排名。
# 6.6 Memory Mapped Files
我们会面临将文件加载到内存中对其处理的场合,由 mmap 系统调用函数提供。而使用 eager 策略将其加载到内存中的代价往往较高,因此操作系统一般采用懒加载策略。
mmap 接受一个虚拟地址(VA)、长度(len)、保护、标志位、文件描述符和偏移量,表示从文件描述符对应的文件的偏移量的位置开始,映射长度为 len 的内容到虚拟内存地址 VA,同时我们需要加上一些保护,比如只读或者读写。
具体实现中,我们使用 VMA(Virtual Memory Area)结构体保存文件描述符、偏移量等,以记录虚拟内存地址对应的实际内容位置。当发生 page fault 时,将磁盘数据读取到内存中。
# 7 中断
# 7.1 真实操作系统实际内存使用情况
真实操作系统中大多数内存被使用,除应用程序用量外,大多数的内存被 buff/cache 占用。当需要使用新的内存时,往往需要从已使用的内存中撤回部分内存以重新利用。
在实际使用中,VIRT(虚拟内存)要远大于 RES(实际使用内存),因此 demand paging 等优化很有必要。
# 7.2 中断硬件部分
当中断发生时,操作系统需要保存当前工作,处理中断,然后恢复原先的工作;在这个意义上,中断与系统调用以及 page fault 的处理很类似。但中断有其特殊性:
- 中断与 CPU 当前执行的任务无关。
- CPU 与中断发生的设备并行运行。
外设连接到 CPU,CPU 通过 PLIC(Platform Level Interrupt Control)处理外设的中断。PLIC 路由中断到 CPU 的一个核以进行处理,当处理完毕,CPU 会通知 PLIC;当没有空闲的核时,PLIC 保留中断直至被处理。
# 7.3 设备驱动
驱动即内核中用以管理设备的代码,一般分为 bottom 和 top 两部分。
bottom 是中断 handler,由 CPU 调用以处理中断;top 是供用户进程及内核其他部分调用的接口。
驱动中存在 buffer,bottom/top 均会向 buffer 中读写数据。
对驱动编程即找到设备在物理地址空间上的位置,并使用 store/load 对其进行操作和控制。
# 7.4 xv6 中的中断
RISC-V 有如下与中断相关的寄存器:
- SIE(Supervisor Interrupt Enable),S 负责软件中断,I 负责定时器中断,E 负责外设中断。
- SSTATUS(Supervisor Status),可用来控制关闭和打开中断
- SIP(Supervisor Interrupt Pending),用来判断中断的类型
- SCAUSE:标志 trap 发生原因是中断或其他
- STVEC:trap 发生的位置,以便完成后恢复
# 中断处理代码
start函数中将中断设置在 supervisor 模式,然后设置 SIE 寄存器接收中断,再初始化定时器。

- 在
main函数中处理中断

- 处理 consoleinit。初始化锁,然后初始化 uart

- 初始化 uart。关闭中断,设置波特率,设置字符长度为 8,重置 FIFO,开启中断。之后 uart 可以生成中断。

- 初始化 plic。决定 plic 接收哪些中断并路由。

- 使用 plicinithart 决定对哪些中断感兴趣

- 调用 scheduler 函数以设置 SSTATUS 寄存器,使 CPU 能够接受中断


# 7.5 UART 驱动 top
以 shell 输出提示符 $ 到 console 为例:
- 在 main 函数中同过 mkmod 系统调用创建 console,再通过 dup 创建 stdout 和 stderr,从而得到三个指向 console 的文件描述符 0、1、2。

- shell 打开 console 的文件描述符,向文件描述符 2 打印
$。

- 上一步中的
fprintf发起系统调用write,由filewrite判断是设备类型,最终调用consolewrite函数。either_copyin拷入字符,使用uartputc写给 UART 设备。

- uart 中定义了一个环形 buffer。
uartputc函数中先判断环形 buffer 是否已满,若已满则 sleep 一段时间以让出 CPU,否则将数据写入 buffer,然后调用uartstart函数。


uartstart通知设备执行操作。首先检测设备是否空闲,若空闲则从 buffer 中读取数据并写入 THR(Transmission Holding Register)寄存器以发送数据。当数据到达设备,系统调用返回。

# 7.6 UART 驱动 bottom
当一个中断由 PCIE 发送给 CPU:
- 清楚 SIE 相应位的 bit,以防止被其他中断打断。
- 设置 SEPT 寄存器为当前 pc,以便之后恢复
- 保存当前 mode(如 user mode)
- 将 mode 设置为 Supervisor mode
- 将 pc 置为 STVEC 的值(即 trap 处理程序的地址),进入 usertrap
usertrap调用devintr,通过 SCAUSE 判断是否来自外设的中断,然后使用plic_claim获取中断。

plic_clame函数中 CPU 告知 PLIC 自己要处理中断,返回中断号

- 若接收到的是 UART 中断,则调用
uartintr函数,从 UART 的接受寄存器中读取数据,然后将数据传给consoleintr

# 7.7 中断相关并发
中断相关的并发包括以下几类:
- 设备与 CPU 并行。称为 producer-consumer 并行。
- 中断停止当前程序运行。中断不仅会打断用户空间代码,也有可能打断内核空间代码,而内核空间代码某些不应该被打断。
- 驱动的 top 和 bottom 并行执行。这也意味着它们可以在两个 CPU 上执行,需要通过锁来共享数据。
驱动中包含一个环形 buffer,大小为 32 个字节,它有两个指针:读指针和写指针。当向 buffer 中写入数据时写指针加,读数据时读指针加;两指针相等时表示 buffer 是空的。
producer-consumer 并发中,producer(在示例中是 uartputc)可以一直向 buffer 中写入数据,直到 buffer 满了,暂时 sleep;consumer,即中断 handler 函数(在示例中是 uartintr)当发生中断时从 buffer 中读数据,直到 buffer 为空。
# 7.8 中断的演进
当一个快设备的场合,中断发生过快以至超出 CPU 的处理能力,这时我们往往使用 polling(轮询);而对慢设备使用中断。在一些场合可以动态切换轮询和中断(如网卡的 NAPI)。
# 8 多线程和锁
# 8.1 为什么要使用锁
# 为何我们倾向于使用多线程提高性能
自 2000 年开始,CPU 的时钟频率几乎不再增加,因此 CPU 的单线程达到了一个极限;而 CPU 的晶体管数量持续增加,因此我们倾向使用多核的方式提高计算机性能。
# 锁的优缺点
当我们同时使用多个核时,需要使用锁来协调多线程时数据的更新,以确保共享数据的正确性以及避免 race condition 的发生。
但是锁同时也会带来性能损失,使程序再次变成串行。
# 8.2 锁如何避免 race condition
# 什么是锁
锁即是一个对象,它有两个方法:
- acquire。acquire 接受一个指向 lock 的指针,表示获得一个锁。同一时间只能有一个进程获得锁。
- release。release 同样接受一个指向 lock 的指针,表示释放一个锁。在锁被释放之前,其他尝试获得锁的进程阻塞。
在锁获得之后、被释放之前,这之间的代码区域被称为 Criticle section,它通常会原子性地更新数据。
# 8.3 什么时候使用锁
当两个进程共享同一数据结构,且其中一个进程想要更改共享的数据结构时需要加锁。
# 8.4 锁的特性和死锁
# 锁的特性
- 避免丢失数据更新
- 打包多个操作,使其具有原子性
- 维护共享数据的不变性
# 死锁
死锁即由于锁的原因导致程序永远阻塞。
最简单的死锁是重复获得一个未被释放的锁。对于多个 CPU 的场合,由于锁的获得和释放的顺序不正确,可能导致 deadly embrace,即两个或更多进程间因互相等待锁的释放而造成的死锁。
因此我们需要以合理的顺序获得和释放锁,这要求对锁进行排序,但该操作又会破坏程序的模块化。
# 8.5 xv6 自旋锁的实现
# 自旋锁的结构
xv6 中自旋锁的定义如下:

locked 表明是否上锁,name 是锁的名称,CPU 表示当前锁被哪个 CPU 持有。
# 获取锁

获取锁的最大挑战是保证设置 locked 字段的操作的原子性,这时由 amoswap 指令实现的。它接受一个地址和两个寄存器 r1,r2。它会先锁定地址,将地址中的数据保存到一个临时变量,然后将 r1 中的数据写入地址,再将临时变量中的数据写入 r2,最后解锁地址。
在流程中最重要的是 lock_test_and_set 循环。该函数实现了 atomic swap 操作:若锁未被持有,则 locked 字段为 0,这时将其设为 1,然后返回原数值 0,退出循环;若锁被持有,则 locked 字段为 1,这时再次对其写入 1,返回原数值 1,继续循环。

# 释放锁

lock_release 同样使用原子方法将 locked 字段置为 0,从而实现锁的释放。

# 9 线程切换
# 9.1 线程概述
# 为何使用多线程
- 希望计算机具有分时性,在同一时间能够执行多个任务。
- 多线程有时能够合理组织程序,降低程序复杂度。
- 多线程可通过并行计算提高计算机性能。
# 线程的定义
对同时多任务编程的抽象,可被认为是串行执行代码的单元。线程具有状态,因此我们可以随时保存其状态并暂停或恢复它。线程的状态包括:
- 程序计数器(PC),表示当前线程执行的位置
- 保存变量的寄存器
- 程序的栈,记录了函数调用情况,同时反映当前线程的执行点
# 多线程并行
多线程并行一般有两种策略:在每个 CPU 上运行一个线程,以及在一个 CPU 上运行多个线程。
在 xv6 中,内核线程共享内存,而用户线程独立运行;对于更复杂的 Linux 系统,一个用户进程也往往包含多个线程。
# 9.2 线程调度
# 线程系统遇到的挑战
- 如何实现线程切换。线程切换的过程称为线程调度,每个 CPU 都实现了一个线程调度器
- 决定在线程切换时保留哪些信息以及如何保存。
- 如何处理运算密集型线程
# 如何处理运算密集型线程
运算密集型线程无法自愿出让给其他线程,因此需要从长时间运行的运算密集型线程中撤回对 CPU 的控制以转交给其他线程使用。
处理方法是使用定时器中断,强制从用户空间进程获得 CPU 控制权。中断处理程序使得 CPU 出让给线程调度器,以便完成线程切换。
这里涉及两个流程:
- pre-emptive scheduling。即使用户代码未出让 CPU,定时器中断仍然强制取得 CPU 控制权,并出让给线程调度器。
- voluntary scheduling。内核中用户进程对应内核线程代表用户进程出让 CPU。
线程分为以下几类,分别对应以下几种状态:
- 当前 CPU 上运行的线程,对应 RUNNING 状态
- 等待 CPU 运行的线程,对应 RUNABLE 状态(即能够被执行)
- 没有在等待 CPU 运行的线程,可能在等待 I/O 或其他事件,对应 SLEEPING 状态
线程切换实际上就是将一个 RUNNING 线程转换成一个 RUNABLE 线程,在切换过程中,需要拷贝其 CPU 状态(程序计数器和寄存器)到内存。
# 9.3 xv6 线程切换
# 线程切换流程
对于一个触发中断的用户程序来说,其用户空间状态保存在 trapframe 中,其对应内核线程的内核寄存器保存在一个 context 对象中,以供恢复使用。
线程切换流程如下:
- 当从一个用户进程切换到另一个用户进程,需要从第一个用户进程进入到内核,保存进程状态并运行它的内核线程。
- 从第一个用户进程的内核线程切换到第二个用户进程的内核线程。
- 第二个用户进程的内核线程暂停自己,并恢复第二个用户进程的用户寄存器
- 第二个用户进程继续执行。
# 实际线程切换流程
在第二步中,一个内核线程并不直接切换到另一个内核线程,而是切换到这个 CPU 对应的调度器线程,并由调度器线程(同样是一个内核线程)切换到下一个内核线程。
# 线程切换程序

proc 记录了进程状态相关的字段,其中:
- trapframe 字段保存用户空间线程寄存器
- context 字段保存内核线程寄存器
- kstack 表示当前进程内核保存函数调用的位置
- state 保存进程状态:RUNNING、RUNABLE 或 SLEEPING
- lock 字段是锁

在代码中创建了两个计算密集型线程,当定时器中断发生时,devintr 函数中使用 yield 让出 CPU 并允许线程切换。

yield 函数获取进程的锁,以阻止其他 CPU 调度器线程由于状态被改变为 RUNNABLE 而运行该进程;改变进程状态为 RUNNABLE,接着调用 sched 函数:

sched 先进行合理性检查,然后利用 switch (核心)函数将内核线程寄存器保存在 p->context 中,然后从 c->context 恢复当前 CPU 调度线程寄存器,从而执行 CPU 调度线程。
# 10 睡眠和唤醒
# 10.1 线程切换过程中锁的限制
- 不允许进程在执行 switch 过程中持有其他锁
- 调用 switch 函数过程中,必须持有 p->lock
# 10.2 Sleep&Wakeup
# Sleep&Wakeup 有什么作用
当我们需要等待一个 I/O 事件时,通常会出让 CPU,此时调用 Coordination(协调机制)。在 xv6 和大多数 Unix 操作系统中,Coordination 是通过 Sleep&Wakeup 方式实现的。
# Sleep&Wakeup 的机制
当一个进程需要等待某个时间,会调用 sleep 函数并等待特定条件;当条件满足,代码调用 wakeup 函数以唤醒进程。
sleep 和 wakeup 往往是成对出现的。它们之间通过 sleep channel 进行链接,以决定 wakeup 所唤醒的是哪个进程。
对于 sleep,它接受一个 sleep channel 参数,然后将进程的状态设为 SLEEPING,表示进程不运行。
对于 wakeup,它检查进程状态,如果进程状态是 SLEEPING 且对应的 channel 是 wakeup 接收到的参数,则将进程状态设置为 RUNNABLE。
# 10.3 Lost Wakeup
lost wakeup 是指内核发起唤醒信号但未能成功唤醒进程的情况。
其发生原因之一是:sleep 在释放锁之前,进程未进入 SLEEPING 状态,此时中断处理程序获取锁并调用了 wakeup,导致唤醒未能生效,从而使进程一直处于 SLEEPING 情况。
解决方法是:sleep 获取一个锁作为参数,当获取进程锁后才释放传入的锁;wakeup 同时获取两个锁。
# 10.4 exit
我们使用 exit 系统调用以释放一个进程。
在杀死线程过程中,该线程可能正在更新复杂内核数据,或是持有重要系统资源(互斥锁等),因此 exit 无法在进程运行时执行。
exit 的流程如下:
- 关闭所有已经打开的文件
- 释放目录引用
- 如果有子进程,设置子进程的父进程为 PID 为 1 的进程(init 进程)
- 使用 wakeup 唤醒父进程
- 将当前进程的状态设置为 ZOMBIE,此时并未释放全部资源
- 父进程的 wait 返回,调用 freeproc 释放子进程的剩余资源,子进程的状态设置为 UNUSED
# 10.5 kill
kill 系统调用的功能是:kill 接受一个 PID,然后使该进程停止运行。
kill 的流程如下:
- 扫描进程表单,查找目标进程,将进程 proc 结构体中 killed 位设置为 1。若进程处于 SLEEPING 状态则设置为 RUNNABLE(被唤醒)。
- 进程运行到可安全停止位置时,检查 killed 标志位,若设置为 1,则自愿执行 exit
因此 kill 系统调用十分温和,只有在进程下一次执行系统调用或触发中断时才会退出。
# 11 文件系统
# 11.1 文件系统实现概论
# 文件系统的特性
- 提供了用户友好的文件名以及层级路径名
- 提供了信息的持久化存储
# 文件系统的机制
- 文件系统提供了对硬件的抽象
- 文件系统提供了很好的 crash safety,支持在计算机崩溃后维持文件系统的完好
- 合理的在磁盘上排布文件的方式
- 性能机制。通过 buffer cache 或 block cache,并行等方式加速文件系统的使用。
# 文件系统 API
- open 系统调用创建或打开文件,返回文件描述符。它使用文件路径名确认文件。
fd=open("x/y",O_RDONLY)
- write 系统调用向文件中写数据
write(fd,"abc",3)
- link 系统调用创建链接
link("x/y","x/z")
# inode 和文件描述符
inode 是文件系统中代表文件的对象,通过编号(int)进行区分,它实现了 read 和 write 方法,同时实现了引用计数以支持链接。
文件描述符(file descriptor)主要与用户进程交互,它维护了文件的 offset。
# 文件系统结构

文件系统自底向上结构分别为:
- 文件系统的最底层是磁盘,磁盘提供了持久化存储
- buffer cache/block cache,通过将数据保存在内存中以避免频繁读写磁盘
- logging 层
- inode cache,负责同步
- inode
- 文件名、文件描述符操作 API
# 11.2 文件系统存储设备
# sector 和 block
- sector 是磁盘驱动可以读写的最小单元,通常是 512 字节
- block 是操作系统/文件系统视角的数据,通常是 1024 字节
文件系统运行在 CPU 上,将内部数据存储在内存,会读取 block 形式存储在 SSD 或 HDD 设备上的数据。其 API 包括 read/write。
# 磁盘
文件系统提供了对磁盘的抽象,在文件系统看来磁盘是一个 block 的数组。

下面是一种常见的文件系统磁盘布局(同样是 xv6 的布局):
- block0 要么闲置要么用作 boot sector,包含了启动操作系统的代码
- block1 被称为 super block,描述了文件系统。其保存文件系统的大部分信息。
- block2-block32 是 log 区。其大小可能视文件系统而不同。
- block32-block45 存储 inode,一个 inode 是 64 字节。
- block46 是 bitmap block,占据一个 block,记录数据 block 是否空闲
- 之后是数据 block,存储文件和目录(文件夹)内容
其中,bitmap block,inode blocks,log blocks 被统称为 metadata block,存储文件系统元数据。
# 14.3 inode

一个 inode 占据 64 字节,它包括以下字段:
- type,表明 inode 是文件或目录
- nlink,link 计数器,跟踪多少文件名指向当前 inode
- size,表明文件数据有多少字节
- direct block number,在 xv6 中有 11 个 direct block number 字段,直接指向文件对应的前 11 个块的编号
- indirect block number,指向一个 block,当文件拥有的块超出 direct block number 的数量,则在 indirect block 中记录其他块的数值编号
# 目录(directory)
目录提供了层次化的命名空间。目录包含了 directory entries,每一个 entry 长度为 16 个字节,都是下面这样的数据结构:

- entry 的前两个字节包含了目录中文件或子目录的 inode 编号
- 后 14 个字节包含了文件名或子目录名
# 文件查找流程
对于路径名"/y/x"对应的文件:
- 首先从 root inode 开始查找,文件系统中 root inode 的编号是确定的
- 扫描 root inode 下所有 block,找到 y,假设它的 inode 编号是 251
- 查找 inode 251,扫描其下所有 block,找到 x 并得到对应的 inode 编号
# 文件创建流程
- 在 inode block 中找到一个空闲的 inode 索引,分配给新创建的文件。
- 在 inode 数组中为新创建的文件分配一个 inode 结构体,并初始化文件的属性。
- 在数据块位图中找到一组空闲的数据块索引,分配给新创建的文件。
- 更新 inode block 和数据 block。
- 在父级目录的 inode 中加入新创建文件的目录项,包括文件名和对应的 inode 索引。
- 更新 root inode,修改 size 字段以包含新创建的文件
简单来说,即是分配 inode 并更新新文件的 data block
# block cache
为了减少磁盘开销,以及加速文件读写,通常采用缓存机制。当应用程序读取或写入文件,首先检查块缓存,如果在缓存中则无需访问磁盘。
块缓存中的数据有两种策略:
- 写回策略:数据块的修改不会被立刻写回磁盘,而是在满足一定条件(如 I/O 延迟,缓存阈值,磁盘空闲)时写回并覆盖磁盘原有内容,可以减少磁盘读写
- 强制写入策略:数据块修改立刻写回磁盘,可保证数据一致性,但会增加磁盘开销并影响性能
# 12 崩溃恢复
# 12.1 文件系统崩溃
文件系统安全要求文件系统在遭遇崩溃(文件系统操作过程中的电力故障和内核 panic)恢复后仍然能够正常使用。
文件系统安全通常使用 logging 解决。
# 12.2 logging
# 特点
- logging 保证了文件系统的系统调用是原子性的,从而避免系统调用写了一半的情况
- 支持快速恢复,相比读取全文件系统 block 进行恢复成本要小得多
- 性能高:logging 本身十分高效
# 实现方式
logging 将磁盘分为 log 和文件系统两部分。
- log write: 任何对文件系统的操作都将先写入 log。
- commit op: 当一系列对文件系统的操作结束,使用 commit 提交操作,同时在 log 中记录操作的个数
- install log: 执行操作,将 log 分区的 block 移至文件系统分区即可
- clean log: 清除 log,将 log 中操作个数设置为 0
对于各种崩溃的情况:
- 如果崩溃发生在 1-2,什么都不做
- 如果崩溃发生在 2-4,可以执行第 3 步而不必担心破坏文件系统,因为重复写入是允许的
# log 结构

log 结构如图所示:
- 第一个 block 称为 header block,其中:n 表示有效的 log block 数量,剩下的字段表示有效的 log block 对应的编号
- 接下来的 block 是 log 的数据块。
# 崩溃恢复流程
- 文件系统崩溃后重启,调用 initlog 函数(实际调用 recover_from_log 函数)
- 先调用 read_head 函数从磁盘中读取 header
- 之后调用 install_trans 函数读取 log header 中的 n,然后根据 n 将所有 log block 拷贝到文件系统 block(步骤 3),然后清除 log(步骤 4)
说人话,先读取 header 块,然后分别执行步骤 3 和步骤 4
# 12.3 logging 面临的挑战
# cache eviction(缓存淘汰)
当缓存满了,我们需要选择块进行淘汰(写入磁盘);但并非所有块都是可以写回的(因为要满足操作的原子性)
我们使用 pin/unpin,利用引用计数的方式淘汰未被引用的块。
# 文件系统操作必须适配 log 大小
假设 log block 的最大数量为 30,这意味着文件系统尝试写入的最大 block 数为 30。尝试写入超过这个数值的操作是不允许的(因为会被写入文件系统区域)
因此,一个大的写操作通常被分成多个小的写操作。
另外,buffer cache 的尺寸必须要大于 log(因为需要完整缓存 log 数据)
# 并发文件系统调用
在两个并发的写操作过程中,如果它们总的大小超过 log,有可能发生没有一个操作可以提交的情况。
此时,我们需要保证写的总 log 数小于 log 区域大小。我们可以通过 group commit 实现,即将同时提交多个操作(多个操作作为一个原子行为)。
# 13 文件系统性能和快速崩溃恢复(以 ext3 为例)
# 13.1 为什么学习 logging
- logging 可以用在任何已知的存储系统故障恢复流程中
- log 在分布式系统中也有大量应用
- log 本身有很多有趣机制
# 13.2 logging 系统规则
- write ahead rule:需要在 log 中定义好所有原子性更新然后才能应用,这是 logging 实现故障恢复的基础
- freeing rule:在 log 中所有写操作已经被更新到文件系统之前不能释放 log
# 13.3 xv6 logging 方案的缺陷
xv6 logging 方案的最大缺陷在于性能。在每次 commit 之后,需要执行多个写磁盘操作,这些操作是同步的,又因为磁盘读写相对较慢,因此耗时很长。
另外,每个 block 需要被写两次(一次 log,一次文件系统)。
# 13.4 ext3 数据结构
# 内存中
- block cache,用以缓存数据
- transaction(可以粗略翻译成事务) 信息,包括序列号,修改的 block 编号(cache 中的),handle(读写 cache 的系统调用)
# 磁盘中
- 文件系统树,包括 inode、文件、目录
- bitmap block,标记 data block 是否空闲
- log 区域
# 13.5 ext3 对 log 的改进

ext3 的 log 包含以下部分:
- 第一个 block 被称为 super block,其中包含了第一个有效 transaction 的起始位置(log 分区中的 block 编号)和序列号
- 之后的块均用来存放 transaction,对一个 transaction,它的数据结构如下:
- 首先是一个 descriptor block,它与 header block 类似,包含 log 数据对应的实际 block 编号
- 然后是对每一个 block 的更新数据
- 最后是一个 commit block
# 13.6 ext3 性能提升措施
# 异步的系统调用
异步的系统调用即是应用程序调用文件系统的系统调用,但是仅修改完毕缓存中的 block 即返回,不去执行耗时更长的写磁盘操作。
与此同时,文件系统在后台并行地进行写磁盘操作。通过这种方式,实现了 I/O 并发。
其优点在于,异步的系统调用加速了应用程序的运行,同时使得大批量的执行成为可能
其缺点在于,系统调用的返回结果不表示写操作的完成(也就是说,即使应用程序中写操作返回,我们也不能想当然地以为数据已经保存到磁盘上)。因此,在 crash 之后,我们要么拿到新文件(写操作完成),要么拿到旧文件(写操作未完成)。问题就在于,我们不知道拿到的是新文件还是旧文件。
为了保证异步 I/O 能够拿到可预期的结果,我们使用了 fsync 系统调用。它接受一个文件描述符,保证与该文件相关的写操作全部完成之后返回。但 fsync 会牺牲异步 I/O 带来的性能,因此通常只在必要的地方使用。另外,fsync 有时也被称为 flush。
# 批量执行
批量执行即是将多个操作打包成一个操作以统一执行。具体来说,ext3 同一时间只会有一个打开的 transaction(创建周期一般是 5s),在这 5s 之中,所有的操作均会打包在这个 transaction 之中;待结束之后统一提交执行。
注意,ext3 在内存中执行的数据结构与 log 中不同:在内存中,有一个 transaction 打包批量执行系统调用,然后一次性将变更内容提交到 log 中持久化;此时 log 中可能存在多个已经 commit 的 transaction,当它们执行完毕(将数据写入 data block)时清空当前 transaction
它的好处在于:
- 避免查找和写元信息(descriptor block 和 commit block)的固有性能损耗
- 对于多次修改同一 block 的情况,可避免多次不必要的磁盘读写,现在可以在内存中完成
- 向磁盘中连续的 block 写入比写入零散的 block 效率更高。
# 并发
ext3 的并发体现在:
- 允许多个系统调用同时修改当前的 transaction
- 允许不同状态的 transaction 存在:内存中一个打开的 transaction 接受系统调用,log 中多个 transaction 可以写数据,以及正在被释放的 transaction
# 13.7 ext3 系统调用
// 标志transaction的开始,获取一个handle
h = start()
// 获取要修改的block对应的缓存
get(h, block_number)
// 修改缓存的内容,略
...
// 标志transaction的结束
stop(h)
我们需要 start 和 stop 来标志一个 transaction 的起始,以便我们能够获得当前事务的个数。
# commit
当全部 transaction 结束,我们可以提交操作:
- 阻止新的系统调用(因为同一时间只有一个接收系统调用的 transaction),系统调用等待
- 等待这个 transaction 中的系统调用完成,即数据已经更新到 cache 中。
- 开启一个新的 transaction,以接收系统调用
- 更新 descriptor block,其中包含所有被修改了的 block 编号
- 将 cache 中的 block 写入 log
- 等待前两步写 log 操作结束,写入 commit block
- 等待写 commit block 结束,则表示当前 transaction 抵达 commit point(在之后遇到 panic 则退回此处继续执行)
- 将 transaction 中 block 写入文件系统实际位置
- 释放 transaction,重用空间
# 恢复
crash 并重启,意味着我们丢失了内存中的所有数据,而磁盘中的数据被保留。
crash 可能打断任何正在进行中的 transaction,包括正在 commit 的以及正在向文件系统写 block 的。
- crash 并重启,读取 super block,得到 log 起始位置;然后线性扫描直到找到 log 结束位置。
- 当某个 commit block 后的一个 block 不是 descriptor block,或 descriptor block 无法找到 commit block,则停止扫描,将这个 commit block 认为是最后一个合法位置。
- 然后根据 log 将数据写入文件系统
# 为何不能同时有两个 transaction 接收系统调用
第二个 transaction 可能会读写第一个 transaction 的 block,从而被当作第一个 transaction 执行,从而使第一个 transaction 失去原子性。
# 14 应用程序虚拟内存
# 14.1 应用程序使用虚拟内存需要的特性
- User level trap,内核中的 Page Fault 能够通过 trap 传播到用户空间,用户空间的 handler 可以处理相应的 Page Fault,然后以正常的方式返回到内核并恢复指令执行。
- Prot1,降低内存 Page 的访问权限
- 管理多个 Page 的 ProtN,相当于多个 Prot1,但是成本更小
- Unprot,增加内存 Page 的访问权限
- 能够查看内存 Page 是否 Dirty(被修改过)
- map2,对物理内存映射,一份物理内存对应两份虚拟内存,同时拥有不同的访问权限
对于 xv6,没能实现上面的任何一个特性,但是现代 Unix 系统具有以上特性。
# 14.2 支持应用程序使用虚拟内存的系统调用
# mmap
mmap 接收某个对象(文件等),将其映射到调用者的地址空间。其参数如下:
- 想要映射到的特定地址。null 表示由内核选择
- 想要映射的地址段长度 len
- Protection bit,如 R|W
- flags(略)。MAP_PRIVATE 表示更新文件不会写入磁盘。
- 传入的对象,如文件描述符等
- offset
addr = mmap(null, len, R|W, MAP_PRIVATE, fd, offset)
上面的系统调用表示的语义是:将文件描述符指向的文件内容,从起始位置加上 offset 的位置开始,连续 len 长度的内容,映射到特定的内存地址。
通过这样的方式,可以使用普通指针操作,而无需使用 read/write 系统调用即可从磁盘读写文件内容。
mmap 还可被用来映射匿名内存,作为 sbrk 的替代方案,向内核申请物理内存,然后映射到特定虚拟内存地址。
# mprotect
mprotect 可以修改映射到虚拟内存地址空间的对象的虚存访问权限。
mprotect(addr, len, R)
如上面的系统调用将 addr 到 addr+len 地址设置为可读,任何写(store)操作将会触发 Page Fault。
# munmap
munmap 可以移除一个地址或一段内存地址的映射关系。
munmap(addr)
# sigaction
sigaction 的应用场景是:当应用程序设置的 signal 触发则调用特定函数。它接受一个信号和一个 handler。
# sigalarm(非标准 Unix 接口)
sigalarm 类似 sigaction,但它类似定时器,每隔一段时间就调用 handler。该功能也可通过 sigaction 实现。
# 14.3 虚拟内存系统如何支持用户应用程序
# VMAs:如何实现内存映射
VMAs 即 Virtual Memory Areas,它会记录一些有关连续的虚拟内存地址段的信息。
一个地址空间中可能包含多个 section,每个 section 都有一个 VMA 对象,其中的所有 Page 都对应这个 VMA 对象。VMA 可以表示进程映射关系。
假设进程中存在一个 mmap file,对于这段地址有一个 VMA 与之对应,VMA 中会包括文件权限以及文件描述符、offset 等信息。
# user level trap
- segfault 事件传播到用户空间
- 通过 upcall 在用户空间运行 handler
- handler 返回内核代码
- 内核恢复被中断的进程
# 14.4 大缓存表
缓存表即是一个记录运算结果的表单。它有些类似预计算,即提前计算好相应内容,需要时直接在表单中查取结果。
对于一个大的缓存表来说,其可能大于物理内存。我们使用一个虚拟内存 page,而不为其分配任何物理内存。当触发 Page Fault 时,分配物理内存。
当物理内存达到上限,我们可以回收部分物理内存 page(修改这些物理内存的 PTE 权限,使访问时能够出发 Page Fault。
# 14.5 copying GC
在 copying GC 中,heap 被分为 from 和 to 两个部分,应用程序从 from 空间申请内存。
copying GC 的基本思想是将仍在使用的对象拷贝到 to 空间。
在 GC 开始后,从根节点开始,依次将它的子节点拷贝到 to 空间(被称为 forward)。为了记住已经被拷贝的对象,会在 from 空间中保留一个 forwarding 指针。
GC 结束之前,from 空间所有对象被丢弃。
应用程序只能使用 to 空间中的对象。每次获取对象之前,需要检查对象是否在 from 空间(即指针检查),如果是,则将其 forward 到 to 空间。
因此 copying GC 有以下缺点:
- 每次解引用(获取对象)都需要复数指令,增加了应用程序的开销
- 不能很好地支持多线程 GC,存在资源抢占问题。
# 14.6 使用虚拟内存特性的 GC
我们可以利用虚拟内存减少指针检查损耗和并行运行 GC。它的思想是:将 to 空间再做划分,包含 scanned,unscanned 两个区域。则:
- 在程序开始,整个空间都是 unscanned。
- 开始 GC 时,拷贝根节点对象到 to 空间,to 空间的 unscanned 权限为 None。当应用程序第一次使用根节点会得到 Page Fault。
- 然后在 Page Fault Handler 中,GC 扫描所有对象,将对象指向的其他对象从 from 空间 forward 到 to 空间。以 root 节点为例,根节点指向两个对象,将这两个对象拷贝到 to 空间的 unscanned 区域,而根节点被标记为 scanned(因为自身和子节点都在 to 空间),之后恢复对应内存 page 的权限。
这种方式具有以下优点:
- 无需对指针做额外检查(因为已经通过硬件完成)
- 简化 GC 并发,通过硬件引入显式同步机制,避免资源抢占
另外,通过 map2 为 GC 和应用程序提供了不同的访问权限,从而使 GC 获取读写内存 page 的能力。
# 15 微内核
# 15.1 宏内核
宏内核表示操作系统内核是一个完成各种事情的大的程序。
# 优势
- 接口高度抽象,可移植
- 可以向应用程序隐藏复杂度,从而使应用开发变得简单
- 由内核管理资源,可以简化应用程序的处理逻辑
- 集成性强,各个系统之间调度简易快速
- 内核代码拥有最高权限
# 缺陷
- 庞大复杂,因此更容易遇到 Bug 和漏洞
- 内核倾向于实现通用性,因此包含了各种功能,但是这些功能不一定都会用到,从而导致效率降低以及优化困难
- 内核存在许多限制,应用拥有较少的自主权,从而削弱抽象能力
- 可扩展性弱
# 15.2 微内核
内核仅支持进程/任务/线程,以及 IPC 作为消息的传递途径。其他原本由内核提供的服务,如文件系统等,现在作为用户进程运行。
以 VIM 读取一个文件为例,通过 IPC 发送一条消息到文件系统进程。文件系统发送一个 IPC 到磁盘驱动程序,磁盘驱动程序与磁盘交互。磁盘驱动返回一个磁盘块给文件系统,文件系统通过 IPC 发送数据给 VIM。
# 优点
- 审美。宏内核大且复杂,更难精细化设计。
- 安全。更少的代码意味着更少的 Bug。同时也更容易测试。
- 易优化。小内核意味着优化更加容易。
- 速度。小内核意味着没有多余功能,因此速度更快。
- 自由。小内核设计限制较少,提供给应用程序更多的灵活性。
- 将内核拆分到用户空间使得代码更加模块化。
- 用户空间代码相比内核更加容易修改,同时易于定制。
- 将操作系统放在用户空间使得其更为健壮(因为可以重启服务)。
- 可以在微内核上模拟或运行多个操作系统。
# 挑战
- API 需要尽可能少,但却能够实现大部分功能。
- 需要开发用户空间服务以实现系统操作的其他部分。
- IPC 需要足够快。
- 由于服务被拆分,在集成时优化空间较小,性能可能相比宏内核更低。
# 15.3 L4 微内核
L4 是最早的一批可以工作的微内核。
# 特点
- 只有 7 个系统调用。相比之下,Linux 约有 350 个系统调用,xv6 有 21 个系统调用。
- 代码少。只有 13000 行代码,只有 Linux 代码的几十分之一。
- 只包含非常基础的抽象,包括 Task、线程、地址空间、IPC。每个 Task 中有多个线程。每个线程有一个标识符,可以通过其实现 IPC 通信。
# 系统调用
- Threadcreate:提供一个地址空间 ID (或者说 Task)并创建一个新的线程。如果 Task 不存在,则创建一个新的 Task。
- Send/Recv:IPC 发送和接收信息
- Mapping:映射内存 Page 到当前 Task 或其他 Task 的地址空间。
- Privileged Task:将硬件控制寄存器映射到自己的地址空间。
- 将中断转换为 IPC 信息。
- 一个 Task 可以设置内核通知自己另一个 Task 的 Page Fault。
# L4 做的事
- 线程切换。它完成线程切换的方式几乎和 xv6 一致。
- Pager。Pager Task 通过 IPC 实现 Page Fault Handler。
# 15.4 IPC 优化
# 一种慢的设计
通过异步 buffer,使用 send 系统调用将消息写入 buffer,另一边通过 recv 系统调用接收。
因此:
- 为了实现消息的发送和回复,需要两个 buffer 以及 4 个系统调用。
- 进行了 8 次用户空间和内核空间的切换(每次系统调用切换 2 次)。
- recv 时需要等待数据
- 至少需要一次线程调度和上下文切换。
# 优化 IPC
- 同步。发送者需要等待接收者。P1 在内核中直接跳转到 P2 的用户空间。这种方式不需要 buffer。通过这种方式,省略了上下文切换或线程调度。
- 只需知道两端数据所在的内存地址即可直接在用户空间中拷贝消息,而不必拷贝到内核。
- 如果消息只有几十个字节(极小),可以在寄存器中传递而无需拷贝。
- 对于长消息,可以共享 Page。
- 对于 rpc,存在一个 call 系统调用,可减少一般的内核态和用户态切换。
通过以上优化,对于短 rpc 请求,可以使速度提升 20 倍。
# 15.5 运行在 L4 上的 Linux
对于使用微内核实现传统操作系统的情况,我们需要在用户空间实现内核未能提供的全部服务。而另一种更加容易的方式是,将现有的操作系统内核(Linux)作为用户程序运行在微内核之上。
由于 Linux 区分用户态和内核态,而在用户空间无法访问硬件,因此需要通过 L4 系统调用或 LPC 对硬件进行控制。
具体实现方法是:Linux 内核作为一个 L4 Task,而每个 Linux 进程又作为一个独立的 L4 Task。缺点是,Linux 失去了进程调度的能力,因为现在由 L4 完成。
# 15.6 微内核思想的影响
- 微内核使用更加灵活的方式使用虚拟内存,其结果是 mmap 系统调用合并到了 Linux 等主流操作系统中。
- 将操作系统作为应用程序运行在另一个操作系统上,这种思想是虚拟机的实现基础。
- 服务可扩展的思想,使得 Linux 也引入了可加载的内核模块,从而允许修改 Linux 的工作方式。
- IPC 的思想也在 macOS 中存在应用。
# 16 虚拟机
# 16.1 虚拟机概论
# 什么是虚拟机
虚拟机是对计算机的一种模拟。
虚拟机的底层是 Host 空间,其上运行着一个 VMM(Virtual Machine Monitor),它取代标准的操作系统内核与硬件进行交互。
其上层被称为 Guest 空间,其中有一个或多个 Guest 操作系统内核。Guest 空间又有两种模式:Guest Supervisor Mode 以及 Guest User Mode。
# 为什么使用虚拟机
- 运行多个低强度服务而无需物理机,节省时间和资金
- 易管理
- 便于内核开发和调试
- 通过 VMM 提供的抽象以实现更多功能,如快照等。
# 16.2 Trap
实现虚拟机的一种方式是软件模拟全部寄存器,但性能极慢,因此我们往往将指令运行在真实 CPU 上。
- 我们将 Guest kernel 运行在 User Mode。
- 当需要使用特权指令,会触发 trap 并走回 VMM,从而获取控制权。
# 16.3 Emulate
VMM 会为每个 Guest 维护一套虚拟状态信息,包括虚拟的 STVEC 寄存器、SEPC 寄存器等特权寄存器。当读取 SEPC 寄存器,VMM 会将虚拟 SEPC 寄存器拷贝到真正的 SEPC 寄存器,从而使 VMM 读到虚拟 SEPC 寄存器。
Guest 运行在用户空间,当需要运行特权指令时,trap 到 VMM(VMM 运行在内核态),通过 VMM 模拟指令,这种方式被称为 Trap and Emulate。
VMM 需要保存以下虚拟状态信息:
- VMM 需要跟踪 Guest 的状态,防止用户空间应用非法调用特权指令,因此会在虚拟状态信息中保存 Guest kernel 的 mode。当 sret 被调用时,VMM 更新 mode 为 user mode。
- hartid,代表 CPU 核的编号,判断当前模拟的是哪个 CPU
# 16.4 Page Table
VMM 会生成一个新的 Page Table 来模拟 Guest 的 Page Table。也就是说,Guest 的物理地址并不对应真实物理地址
VMM 维护了一个映射表,将 Guest 物理内存地址(gpa)映射到真实物理内存地址,称为主机物理内存地址(hpa)。对每个 Page Table,VMM 会创建一个 Shadow Page Table,它提供了 gpa 到 hpa 的翻译工作。
# 16.5 外设
对于虚拟机来说,需要使 Guest 能够识别需要的外设,包括鼠标键盘、声卡、显卡等。一般有三种实现策略:
# 模拟真实设备
在第一种策略中,VMM 不会映射外设对应的内存地址,而是将其设为无效。当访问这些内存会触发 trap,从而走到 VMM。VMM 根据 trap 信息模拟真实硬件并相应 Guest 指令。
这种方式能够模拟一个不存在的设备,但缺点在于十分低效,因为每次与外设的交互都需要触发一个 trap。
# 提供虚拟设备
第二种策略在内存中格式化了一个命令队列,Guest 系统将读写设备的命令写到队列中。
与此同时,VMM 在后台检查虚拟硬件的命令队列并读取命令,然后将命令应用到一个文件(虚拟磁盘),然后将结果写入命令队列,通知 Guest 命令已执行。
该方式相比模拟硬件能够规避 trap,从而实现更高的性能。
# 对于真实设备的 pass-through
第三种策略最典型的例子是网卡。网卡可以表现为多个独立的子网卡,Guest 可以直接与子网卡进行交互。
# 16.6 硬件对虚拟机的支持
# 为何提供虚拟机支持
- 虚拟机应用广泛
- Trap and Emulate 方案中涉及到大量 trap,性能差
- x86 不适合虚拟化,需要一些具体实现以支持虚拟化
# non-root
一种性能提高方式是将本来 VMM 在软件中保存的虚拟状态信息保存在硬件中。现在,硬件中存在一套独立的,供 Guest mode (non-root mode,相对于 root mode)使用的虚拟控制寄存器,它是真实寄存器在硬件中的拷贝。
因此,Guest 能够不触发 trap 而执行特权指令。
# 系统调用
当 VMM 创建一个新的虚拟机时需要通过一些指令配置硬件。
VMM 在内存中通过一个结构体与 VT-x 硬件交互,称为 VMCS(Virtual Machine Control Structure)。当创建虚拟机时,VMM 会创建一个结构体,并填入配置信息和寄存器初始值,然后通知 VT-x 硬件运行一个新的虚拟机。
- VMLAUNCH:创建一个新的虚拟机,接受一个 VMCS 结构体地址,开始运行 Guest kernel
- VMRESUME:当 Guest kernel trap 到 VMM,需要通过 VMRESUME 恢复至 Guest kernel。
- VMCALL:在 non-root mode 使用,使代码从 non-root mode 退出并通过 trap 走到 VMM。
虽然 Guest 可以不触发 trap 地执行特权指令,但有时需要使代码进入 VMM,如调用 VMCALL 或设备中断。
# Page Table 支持
硬件提供了 EPT(Extended Page Table)寄存器,它指向一个 Page Table,使得 VMM 可以控制 Guest 可以使用哪些内存地址。
当 MMU 翻译 Guest 虚拟内存地址时:
- 将 Guest 虚拟地址(gva)翻译到 Guest 物理地址(gha)
- 通过 EPT 将 Guest 物理地址(gha)翻译成主机物理地址(hpa)
这里 EPT 的作用与 Shadow Page Table 十分类似。
# Dune
Dune 是对支持虚拟机的硬件在 host 中的应用。它支持对进程的管理,使得进程同时拥有 Guest Supervisor mode 和 Guest User mode。
类似一个沙盒
Dune 还支持以一种方便的方式获取 PTE 及其 dirty 位,从而加速进程的垃圾回收。
# 17 内核与高级语言
# 17.1 C 语言实现操作系统的优劣势
# 背景
许多操作系统,如 Windows、Linux、BSD 都是由 C 实现的。
# 优势
- C 语言提供了强大的控制能力,能够完全控制内存分配和释放
- C 语言没有高度的抽象(原文是隐藏的代码,其实就是语言接近底层),与 RISC-V 指令高度对应
- 有直接内存访问能力,可以读写寄存器
- 依赖少,可以裸机运行
# 劣势
很难写出安全的 C 代码:
- buffer overrun:数组越界,栈溢出
- use-after-free bugs:使用了一些已经释放的内存
- 线程共享内存时难以决定释放时机。
其中,buffer overrun 和 use-after-free bugs 经常出现。
# 17.2 高级编程语言实现操作系统的优劣势
这里的高级编程语言主要指一些 GC 语言。
# 优势
- 高级编程语言提供了内存安全
- 高级编程语言提供了类型安全
- 高级编程语言通过 GC 实现了自动的内存管理
- 高级编程语言对并发更友好
- 高级编程语言有更好的抽象,能够编写出更加模块化的代码
# 劣势
- 高级编程语言通常性能更低,因为有一些额外的代价(High Level Language Tax):索引数组元素时检查边界、空指针检查、类型转换
- GC 本身的代价
- 不适合内核编程:
- 没有直接访问内存的能力
- 不能集成汇编语言
- 编程语言的并发与内核并发不一致
# C 与高级语言内核编程对比实验背景
- 使用高级语言构建内核
- 保留 Linux 中最重要部分对等的功能
- 优化性能使其与 Linux 接近
通过以上方式,测量高级编程语言的优劣
# 17.3 Golang 高级语言系统编程
这里使用 Golang 作为对比的高级语言,理由有:
- Go 是一个静态编译的编程语言,其性能相对更好。
- Go 在设计上适合系统编程:
- 能够容易地调用汇编或其他外部代码
- 能够很好地支持并发
- 非常灵活
- 支持 GC
为什么不使用 Rust?因为 Rust 认为高性能语言不应该使用 GC,从而略过了这一问题。该论文到底还是实验性质的。而事实证明,Rust 的确适合内核编程。
# 17.4 Biscuit
Biscuit 即是本次使用 Golang 编写的实验性的操作系统内核。
# 特点
- Biscuit 是一个宏内核,具备用户空间和内核空间。它使用 goroutine 作为内核线程,通过 Go runtime 进行调度。
- Biscuit 提供了一个中间层,从而使得 Go runtime 能够运行在裸机上。
- 相比 xv6 更加复杂,同时具有更高的性能。具备虚拟内存系统、文件系统以及设备驱动。具有 58 个系统调用以及 28000 行代码,相比之下,xv6 具有 18 或 19 个系统调用以及不到 10000 行代码。
# 特性
- 通过 go 的并发机制支持多核 CPU。
- 支持用户空间多线程
- 高性能的日志式文件系统
- 较复杂的虚拟内存系统,使用 VMAs 并支持 mmap 等功能
- 拥有一个完整的 TCP/IP 栈。
- 两个高性能驱动,分别是 Intel 10Gb 网卡以及复杂的磁盘驱动 AHCI
# 应用程序支持
- 每个应用程序有自己的 Page Table
- 用户空间和内核空间内存由硬件隔离,通过 PTE 的 User/Kernel bit 区分
- 每个用户线程有一个对应的内核线程
- 内核线程由 Go runtime 提供的 goroutine 实现
# 系统调用
biscuit 系统调用流程如下:
- 用户线程将参数保存在寄存器中,通过库函数使用系统调用接口
- 用户线程执行 SYSENTER
- 控制权传递给了内核线程
- 内核线程执行系统调用,并通过 SYSEXIT 返回用户空间
# 设计挑战
- 要使 Go runtime 运行在裸机上,却对 runtime 本身做尽量少的修改以便向后兼容
- 安排 goroutine 去运行不同的应用程序。
- 设备驱动,使用一个普通的 gorutine 处理中断。
- heap 耗尽
# 17.5 Heap 耗尽问题
在 xv6 中我们静态分配内存,因此不需要 heap。而在其他正常的内核中,内存是动态分配的,需要有一个 heap。
当应用程序打开许多文件描述符、socket 等,heap 会被逐渐填满。当 heap 没有额外空间时,在 xv6 中返回一个错误;而在 Go runtime 中,new 分配对象必定成功。
针对这种情况(heap 耗尽)一般有以下几种解决方法(原文是 strawman,稻草人,指一种没法达成目的的原案):
- 没有空闲则 panic
- 等待内存分配器(容易造成死锁)
- 没有内存则返回空指针,如果检查到空指针则失败(bail out)
# 17.6 Heap 耗尽解决方案
在系统调用的开始,跳转到内核之前,调用 reserve 函数。它会保留足够的内存以执行系统调用。reserve 函数使得系统调用必定成功。
当没有足够内存的情况,reserve 会等待;由于此时是系统调用最开始,不存在任何锁,因此不需要担心死锁的情况。
在等待的同时,内核能够撤回 cache 并增加 heap 的空余空间。
这种方案有以下优点:
- 内核不需要检查内存分配是否失败
- 因为必定成功,所以不需要错误处理代码
- 不存在死锁的可能(因为根本没有锁)
# 如何计算系统调用需要的内存
通过 go 的 runtime 可以得到函数调用图,再加上类型大小确定,可以计算出总内存大小,即系统调用可能的最大内存。
在实际情况中可能存在内存逃逸,当一个函数返回时,它可能回传一部分内存给调用者,这种现象称为内存逃逸。这部分内存需要加到调用者的内存计数中。
另外,go 的 Slice 会自动扩容,因此需要标准最大容量
# 17.7 评价使用高级语言的收益
# 是否使用了高级语言特性
如果我们避开了任何高级语言特性,那么实验就没有意义了。
事实证明,Biscuit 使用了相当多的 go 提供的高级语言特性,如 allocation、maps、slice、channel(很少使用)、多返回值(最喜欢的特性?)、闭包、defer(稍微使用)、Interface、断言、import
# 高级语言是否简化了代码
有。
- GC 自动地完成了释放内存的工作
- 多返回值对代码风格很好
- map 避免了线性扫描
# 高级语言是否减少了内核 Bug
在 65 个 Bug 当中,至少有 40 个 Bug Golang 直接解决或给出了更好的结果。
# 17.8 评价高级语言的性能损失
# 测试环境
- 裸机(区别于 QEMU)
- 4 核 2.8Ghz Xeon-X3460
- 16G 内存
- 禁用超线程
- 应用程序
- NGINX(1.11.5)-webserver
- Redis(3.0.5)-key/value store
- CMailbench-mail-server benchmark
# 性能是否与 Linux 接近
- 首先关闭 Linux 中所有 Biscuit 不提供的功能
- 吞吐量测试,Biscuit 更慢,mailbench 差 10%,nginx 与 Redis 差 10%-15%
# 高级语言额外的代价有多大
- 3% 的时间用于 GC cycles
- Prologue(确保栈足够大)占用 CPU 时间最多(4%-6%)
- Write barrier(跟踪不同空间指针)时间很少(<1%)
- Safety cycles(空指针检查)占用 2%-3%
测试结果表明代价可接受,当然 GC 的占比在实际环境中很可能更高
# GC 会带来多少损耗
在空闲内存较小时,存在严重的 overhead 现象。为了控制 GC 的 overhead 在 10% 以内,物理内存大小至少应是 heap 的三倍。
# GC 延迟如何
go 的 GC 是一个带有短暂 pause 的并发 GC:会暂停一段极短的时间来执行 write barrier。
- 单个 pause 最大时间为 115 微秒,出现在 Web server 中。
- 一个 HTTP 请求的最大 pause 时间是 582 微秒。
- 超过 100 微秒的 pause 少于 0.3%
最大 pause 时间 582 微秒不理想,但还在可以接受范围内(一个请求允许的最长处理时间大概在数毫秒或几十毫秒)
# go 相对于 c 的代价如何
测试通过 pipe 传输一个字节。
- 1.2K 行 Go 代码,相比之下,C 有 1.8 行代码
- C 比 Go 快约 15%
# 是否应当在一个新的内核中使用高级语言
- 如果性能至关重要(15% 提升),应当使用 C
- 如果想要最小化内存使用,使用 C
- 如果安全更重要,使用高级语言
- 如果性能不是那么重要,高级语言是很好的选择
# 18 计算机网络
# 18.1 计算机网络概述
# 局域网(LAN)
局域网通信由以太网协议决定。一个局域网即是连接在同一网络中的相近主机。它的中心是一个以太网设备,包括交换机或线缆。主机连接在这个设备上,包括电脑、服务器或路由器。
一个局域网的大小是有限的,它最多只能容纳 100 个左右的设备。
# 互联网
互联网是连接多个独立的局域网的网络,它们之间通常由路由器(Router)连接。路由器是组成互联网的核心。
当一个局域网中的主机需要与另一个局域网中的主机通信,需要经过一系列路由器的转发,这种转发被称为(Routing)。
因此,我们还需要使这个局域网中的主机能够寻址到另一个局域网中的主机。
局域网之上的长距离网络通信协议是 Internet Protocol。
# 18.2 以太网
局域网通信协议是以太网协议。
局域网中的两个主机,Host1 和 Host2 之间通过以太网传输 Frame。Frame 即是 packet,指两个主机在以太网传输的一个个数据 Byte。
# packet 数据结构
每个以太网 packet 的数据结构如下:
- Header:包括目的以太网地址、源以太网地址、packet 类型
- payload
以太网地址是一个 48bit 的数字,唯一识别一个网卡。packet 类型告诉接收端主机如何处理 packet。
另外,packet 的开头和结尾还有标志 packet 起始和结束的 bit。
以太网的 48bit 地址是网卡的唯一 ID,前 24bit 表示制造商,而每个网卡制造商有自己的唯一编号;后 24bit 是网卡制造商提供的唯一数字,通常是递增的数字。
# tcpdump 获取 packet
我们通常可以使用 tcpdump 查看以太网 packet,他能够得到:
- 接收 packet 的时间
- 可读的 packet 数据
- 收到 packet 的 16 进制数
packet 结构如下:
- 前 48bit 是一个广播地址,0xffffffffffff,指 packet 需要发送给局域网中所有主机
- 之后 48vit 是发送主机的以太网地址。在 QEMU 中,这个地址由 QEMU 生成。
- 之后 16bit 是 packet 类型。0x0806 表示对应协议是 ARP
- 之后是 packet 的 payload
# 18.3 ARP
ARP 是一个与以太网通信相关的协议,全称是 Address Resolution Protocol,能够动态解析 32bit 的 IP 地址为对应主机的 48bit 以太网地址。
当一个 packet 需要转发给以太网中的另一个主机,这个发送方可能是路由器或局域网中的主机。发送方会先在局域网广播一个 ARP packet,通知包含这个 IP 地址的主机返回其以太网地址。然后如果该主机存在,会向发送方发送一个 ARP response packet。
一个 ARP packet 结构与一个普通的 packet 相同。其 header 中包含了一个 16bit 数(0x0806),表明这是一个 ARP packet。然后接收到该 packet 的主机将这个 packet 发送给 ARP 协议处理代码。
# tcpdump 接收 ARP packet
一个 packet 的数据结构如下:
- 前 14 的字节是以太网 header
- 倒数 4 个字节是 TIP,即发送方想要找出的对应以太网地址的 IP 地址
- 往前 6 个字节是 THA,即目的地的以太网地址,未知的情况下是全 0
- 往前 4 个字节是 SIP,即发送方的 IP 地址
- 往前 6 个字节是 SHA,发送方的以太地址
- 剩下 8 字节表明我们对以太网和 IP 地址格式感兴趣
# header 嵌套
header 是嵌套的,我们需要逐个解析并剥离得到原始的 header
# 18.4 IP
IP 协议能够向互联网上任意位置发送 packet。
如果 IP packet 通过以太网传播,其结构如下:
- 目的以太网地址
- 源以太网地址
- 以太网类型(0x0800)
- IP header
- IP payload
IP header 中关键信息包括:目的 IP 地址(ip_dst)、源 IP 地址(ip_src)、协议(ip_p)
# 18.5 UDP
通过 IP header 我们能够将一个 packet 传递到互联网上任意主机。如果需要传递给主机上的某个应用程序,我们需要使用 TCP 和 UDP 协议。
# TCP
TCP 不仅能够将 packet 发送到正确应用程序,并且包含了序列号等数据结构以检测丢包并支持重传,从而保证数据完整有序传输。
# UDP
UDP 是一种更简单的协议,它只将 packet 发送到对应应用,不提供其他功能。

UDP header 中最重要的字段是 sport 源端口和 dport 目的端口。
# tcpdump 接收 UDP packet

从前到后依次是:以太网 Header、IP header、以及 8 字节的 UDP header,表明源端口是 0x0700,目的端口是 0x6402,第 4-5 个字节表示长度,6-7 个字节是校验和(xv6 未生成,因此是 0)
payload 中显示报文的内容是:a.message.from.xv6。
因此,嵌套关系如下:ASCII TEXT < UDP packet < IP packet < Ethernet packet
# 18.6 网络协议栈
网络协议栈对应报文的嵌套结构,自顶向下是 socket layer、TCP/UDP 层、IP 以及 ARP 层、以太网层(实际是网卡驱动层,直接与网卡硬件交互)
网络协议栈中有一个 packet buffer,这个 buffer 在整个网络协议栈中传递,进行协议解析和数据交付。
这个 packet buffer 就是一个缓存队列,使用其的理由如下:
- 网卡接收方向,短暂应对大流量。IP processing thread 很可能慢于网卡的处理速度,因此需要暂时储存 packet。
- 网卡发送方向,可使网卡空闲时发送大量 packet
- 帮助组件解耦。
# 18.7 Livelock

路由器的性能图如上,其中 X 轴对应接收端网卡的 packet 接收速率,Y 轴是发送端网卡的 packet 发送速率。
图中拟合曲线呈现先上升后下降关系。
上升段:路由器将 packet 从输入网卡拷贝到输出网卡,路由器的发送速率和接收速率一致,因此 X 轴与 Y 轴的值相等
转折点:曲线转折点大概在 5000,这意味着处理一个 packet 大约要消耗 200 微秒(1/5^3x10^6)
下降段:本来路由器的处理速度是恒定的,因此应当会呈现出一个水平线。但事实上多余的 packet 也会生成一个中断,因此每个 packet 都会消耗 CPU 时间,从而使转发 packet 的时间减少
这里曲线的下降就被称为中断的 Livelock。这是由于 CPU 运行着两个独立的任务,由于中断的优先级更高,使得另一个任务占有的 CPU 时间减少。
多余的 packet 会被加入 packet buffer,当 buffer 到达长度上限则丢弃多余的 packet。
# 18.8 解决 Livelock

我们的目的是获得 non-livelock 性能曲线(水平曲线),它只受 CPU 限制的影响
在网卡第一次发生中断时,中断处理函数唤醒处理 packet 的线程,并关闭网卡中断。packet 处理线程在循环中检查网卡并处理 packet,直到没有等待处理的 packet。然后处理线程重新打开网卡中断,并进入 sleep 状态。
由于关闭中断,CPU 运行时间完全用来处理 packet,在高负载下,其性能曲线呈现一条水平曲线
# 19 Meltdown
# 19.1 Meltdown 发生背景
Meltdown 产生的原因是 CPU 优化技术使得用户态和内核态切换时不发生 Page Table 切换,也就是共用同一张页表。而 CPU 的乱序执行又可能导致指令的提前执行。这样我们就能利用一些方式从内存中偷取一些数据。
Meltdown 攻击基本流程如下:

- 在程序中声明一个
buffer[8192],这个 buffer 是普通的用户内存且可被正常访问 - 得到包含想要窃取数据的虚拟内存地址
- 将虚拟内存地址取值并保存在寄存器 r2 中
- 获取寄存器 r2 的低 bit 位
- 将这个值乘以 4096,得到 4096 或 0
- 读取申请的 buffer,要么是
buffer[0],要么是buffer[4096]
这段攻击代码依赖于预测执行和 CPU 的缓存方式
# 19.2 预测执行

预测执行是一种用来提升 CPU 性能的技术
- 在 r0 寄存器保存一个内存地址,可能有效也可能无效
- 内存中还保存了一个 valid 变量,将其加载到 r1 寄存器
- 当且仅当 valid 等于 1 时使用 r0 中的地址,将 r0 地址指向的内容加载到 r2
- 对 r2 寄存器加一,保存在 r3 寄存器
第二行使用 load 指令读取内存数据,该指令需要花费数百个 CPU cycle。分支预测即是第三行基于上一次返回的结果提前执行分支,这是一种 CPU 优化方法,此时第 2 行指令未返回可能就已经执行第 4 行指令。当 load 返回,如果 valid 等于 0,则取消已经执行的代码的效果并重新执行正确的分支。
这里提前执行的分支将值保存在一个临时寄存器中,当分支命中则变成真实寄存器,否则抛弃临时寄存器。
如果 r0 指针无效,当超前执行代码时不会产生 Page Fault。它需要等待 load 返回后才能产生 Page Fault。
# 19.3 CPU 缓存
CPU 分为 CPU 核和 CPU 缓存。
CPU 核负责指令解析,包含寄存器,有加法单元、除法单元以做运算。CPU 核是 CPU 的执行部分。
CPU 缓存设计在 CPU 内部,位于 CPU 核与内存控制器之间,用以加速 CPU 访问内存数据。CPU 包含多级缓存,如果 L1 cache 未命中,则依次向下查找。当所有缓存均未命中,则查取内存数据。
# 19.4 Meltdown 攻击

17 行后代码利用 Flush+Reload 机制(读取 CPU 时间)探索 CPU 缓存,如果 b-a<c-b 则表明 buffer[0] 在 cache 中。
# 19.5 Meltdown 修复
KAISER 或 KPTI 技术:不将内核内存映射到用户 Page Table。
# RCU
# 20.1 使用锁带来的问题
spinlock 的工作是当两个线程可能相互影响时阻止它们并行运行。其缺点在于性能较差。
在只读的场合,我们没有使用锁的必要。但是在读多写少的场合,需要使用锁以避免写对读的影响。但是又回到了 spinlock 带来的性能问题。
因此我们引入了读写锁,它允许多个读取线程和一个写入线程。
# 20.1 读写锁
读写锁有 4 个 API:
- r_lock
- r_unlock
- w_lock
- w_unlock
可以有多个线程获取读锁,从而并行读取数据;或者只有一个线程获取写锁,从而允许其写入数据。

读写锁的简易实现如上图所示,它维护了一个字段 n:
- 当 n 等于 0 时锁没有被任何人持有
- 当 n 等于-1 时,有一个 writer 持有写锁
- 当 n 大于 0 时,表明有 n 个 reader 持有读锁
对 n 的修改依赖于原子指令。
# 读写锁的弊端
读写锁将一个只读操作变成了需要修改锁的计数器的操作,相较原本的只读操作成本高了许多。
因此我们需要一种更高性能的实现,为此我们引入了 RCU
# RCU
RCU(Read-Copy-Update)即是创建一个缓存,将对元素的修改全部作用于这个缓存之上,当 commit 之后写回原数据结构中。
其具体实现流程如下:

RCU 的优点在于其数据读取非常快,对 reader 几乎没有额外负担,而写数据则十分糟糕,因为 synchronize_rcu 操作(确保所有持有旧数据的 CPU 执行了一次上下文切换,从而放弃持有旧数据)耗时严重。
# RCU 总结
- RCU 不是通用的,适用于读远远大于写的场合。
- 不能在原地更新数据,因此只适用于一些小的数据结构,如树或单链表
- RCU 不保证 reader 读取到的是新的数据。
# 如何提高写数据的性能
- 重新构造数据结构使其非共享
- 分离数据:对于频繁写入单不需跨核同步的数据可以为每个 CPU 创建单独的实例从而避免使用锁
- 延迟同步:对于统计计数器,可以为每个 CPU 维护单独的实例,然后读取全部实例并相加。